
Indexing
Introduction
The indexing topology is a topology dedicated to taking the data from the enrichment topology that have been enriched and storing the data in one or more supported indices
- HDFS as rolled text files, one JSON blob per line
- Elasticsearch
- Solr
By default, this topology writes out to both HDFS and one of Elasticsearch and Solr.
Indices are written in batch and the batch size is specified in the Sensor Indexing Configuration via the batchSize parameter. This config is variable by sensor type.
Indexing Architecture
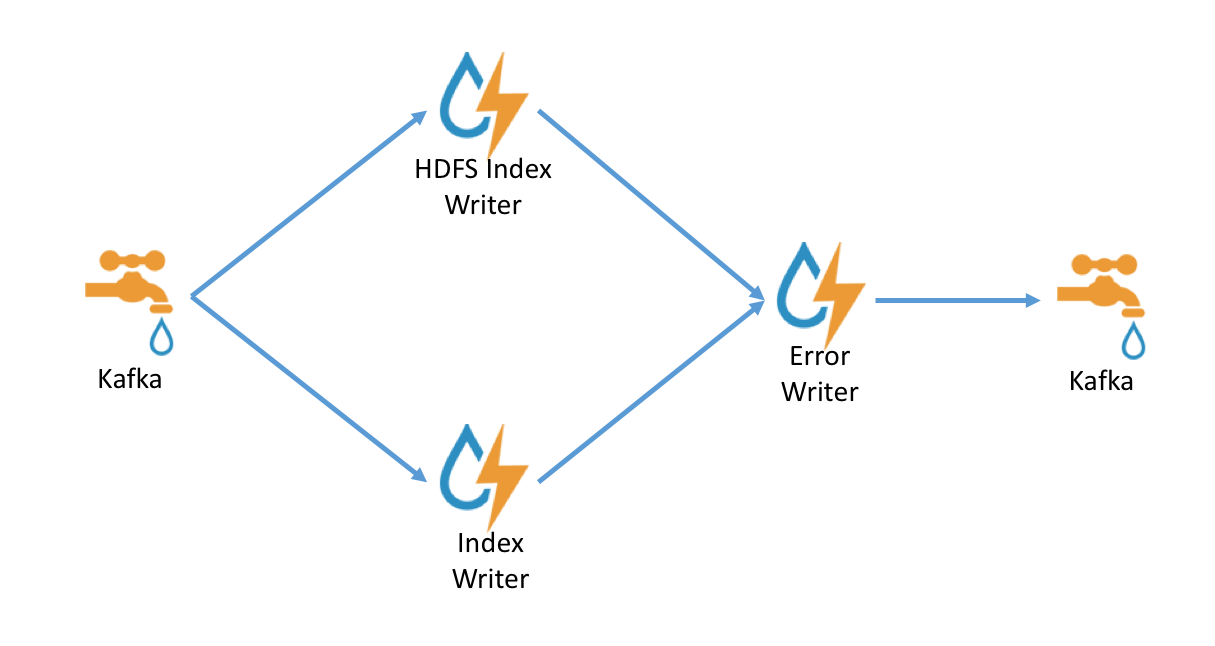
The indexing topology is extremely simple. Data is ingested into kafka and sent to
- An indexing bolt configured to write to either elasticsearch or Solr
- An indexing bolt configured to write to HDFS under /apps/metron/enrichment/indexed
By default, errors during indexing are sent back into the indexing kafka queue so that they can be indexed and archived.
Sensor Indexing Configuration
The sensor specific configuration is intended to configure the indexing used for a given sensor type (e.g. snort).
Just like the global config, the format is a JSON stored in zookeeper and on disk at $METRON_HOME/config/zookeeper/indexing. Within the sensor-specific configuration, you can configure the individual writers. The writers currently supported are:
- elasticsearch
- hdfs
- solr
Depending on how you start the indexing topology, it will have either elasticsearch or solr and hdfs writers running.
The configuration for an individual writer-specific configuration is a JSON map with the following fields:
- index : The name of the index to write to (defaulted to the name of the sensor).
- batchSize : The size of the batch that is written to the indices at once (defaulted to 1).
- enabled : Whether the writer is enabled (default true).
Indexing Configuration Examples
For a given sensor, the following scenarios would be indicated by the following cases:
Base Case
{
}
or no file at all.
- elasticsearch writer
- enabled
- batch size of 1
- index name the same as the sensor
- hdfs writer
- enabled
- batch size of 1
- index name the same as the sensor
If a writer config is unspecified, then a warning is indicated in the Storm console. e.g.: WARNING: Default and (likely) unoptimized writer config used for hdfs writer and sensor squid
Fully specified
{
"elasticsearch": {
"index": "foo",
"batchSize" : 100,
"enabled" : true
},
"hdfs": {
"index": "foo",
"batchSize": 1,
"enabled" : true
}
}
- elasticsearch writer
- enabled
- batch size of 100
- index name of “foo”
- hdfs writer
- enabled
- batch size of 1
- index name of “foo”
HDFS Writer turned off
{
"elasticsearch": {
"index": "foo",
"enabled" : true
},
"hdfs": {
"index": "foo",
"batchSize": 100,
"enabled" : false
}
}
- elasticsearch writer
- enabled
- batch size of 1
- index name of “foo”
- hdfs writer
- disabled
Notes on Performance Tuning
Default installed Metron is untuned for production deployment. By far and wide, the most likely piece to require TLC from a performance perspective is the indexing layer. An index that does not keep up will back up and you will see errors in the kafka bolt. There are a few knobs to tune to get the most out of your system.
Kafka Queue
The indexing kafka queue is a collection point from the enrichment topology. As such, make sure that the number of partitions in the kafka topic is sufficient to handle the throughput that you expect.
Indexing Topology
The indexing topology as started by the $METRON_HOME/bin/start_elasticsearch_topology.sh or $METRON_HOME/bin/start_solr_topology.sh script uses a default of one executor per bolt. In a real production system, this should be customized by modifying the flux file in $METRON_HOME/flux/indexing/remote.yaml.
- Add a parallelism field to the bolts to give Storm a parallelism hint for the various components. Give bolts which appear to be bottlenecks (e.g. the indexing bolt) a larger hint.
- Add a parallelism field to the kafka spout which matches the number of partitions for the enrichment kafka queue.
- Adjust the number of workers for the topology by adjusting the topology.workers field for the topology.
Finally, if workers and executors are new to you or you don’t know where to modify the flux file, the following might be of use to you:
Zeppelin Notebooks
Zeppelin notebooks can be added to /src/main/config/zeppelin/ (and subdirectories can be created for organization). The placed files must be .json files and be named appropriately. These files must be added to the metron.spec file and the RPMs rebuilt to be available to be loaded into Ambari.
The notebook files will be found on the server in $METRON_HOME/config/zeppelin
The Ambari Management Pack has a custom action to load these templates, ZEPPELIN_DASHBOARD_INSTALL, that will import them into Zeppelin.